Technology
Building an AI Agent That Automates Google Maps → Enrichment → Outreach
A technical guide to building a multi‑agent AI system that automates Google Maps data extraction, enrichment, and personalized outreach to create a scalable lead pipeline.
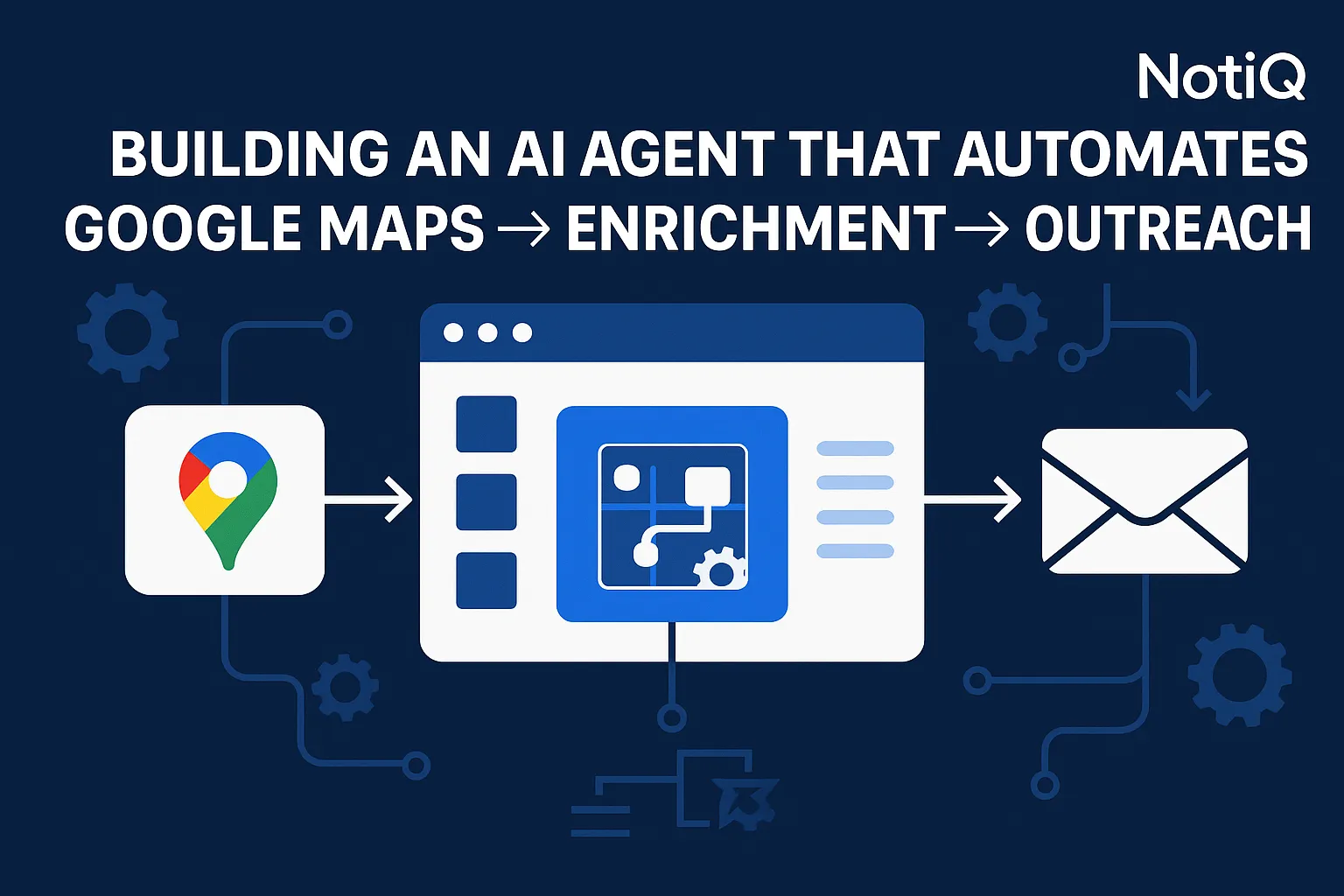
1. Introduction
Local business data is the lifeblood of B2B lead generation, and Google Maps remains the single most comprehensive index of this data globally. For agencies, SaaS platforms, and service providers, it represents an untapped reservoir of potential clients—from dental clinics in Denver to logistics hubs in Hamburg. However, accessing this data at scale is operationally fragile.
Most teams rely on a patchwork of disconnected tools: a scraper that breaks when the browser updates, a spreadsheet for manual cleaning, and a separate platform for email sequencing. This fragmented approach results in data decay, operational bottlenecks, and missed opportunities. Scrapers fail, enrichment tools return inconsistent fields, and by the time data reaches the outreach stage, it is often stale or inaccurate.
The solution lies in moving beyond simple automation scripts to a multi-agent AI workflow. By architecting a system where specialized AI agents handle scraping, enrichment, validation, and outreach orchestration autonomously, businesses can build a pipeline that is resilient, scalable, and compliant.
This guide provides a technical blueprint for building an ai outreach agent system capable of automating the entire lifecycle—from Google Maps discovery to hyper-personalized outreach—while prioritizing reliability and data integrity. As an automation-first platform,NotiQ leverages these multi-agent architectures to transform chaotic data streams into organized, actionable revenue pipelines.
2. Why Google Maps Lead Generation Breaks Without Automation
The allure of Google Maps for lead generation is its breadth, but its infrastructure is designed for human navigation, not automated extraction. This creates systemic fragility for anyone attempting to build a lead pipeline without sophisticated engineering.
Systemic Fragility and Operational Bottlenecks
Traditional workflows often rely on browser automation tools that interact with the frontend of Google Maps. These are notoriously volatile. A minor change in the DOM (Document Object Model) structure of the page can render a scraper useless overnight. Furthermore, aggressive rate limiting and IP-based blocking mean that simple scripts often fail to complete their tasks, leaving you with partial datasets.
Beyond the extraction layer, the data itself is often messy. Inconsistent fields—such as missing phone numbers, generic email addresses (info@), or outdated business hours—create a "dirty data" problem. In manual workflows, human operators must verify this information, a process that is slow and error-prone. Industry benchmarks suggest that without automated validation, data mismatch rates can hover between 10% and 30%, resulting in bounced emails and wasted ad spend.
The Failure of Manual Toolchains
Many growth teams attempt to patch this together using "glue code" platforms like Zapier or Make, connecting standalone scrapers (like Phantombuster) to spreadsheets (like Clay or Airtable). While these tools are excellent for prototyping, they struggle with the complexity of high-volume google maps scraping automation.
• Lack of State Management: If a workflow breaks in the middle (e.g., during enrichment), standard automation tools often lack the context to resume where they left off.
• No Native Retry Logic: If a scraper hits a rate limit, a linear workflow simply fails. It doesn't know how to pause, rotate proxies, or switch to an API fallback.
• Data Silos: Data extraction and outreach often happen in different environments, leading to version control issues and compliance risks.
To build a truly scalable engine, you need a system designed for resilience—one that treats errors as expected events rather than critical failures. This is where NotiQ distinguishes itself as an automation-first platform, moving beyond simple triggers to full-scale orchestration that handles the complexities manual toolchains cannot.
For those building their own solutions, it is critical to understand the constraints imposed by the source. Adhering to Google Places API best practices ensures that your automation respects query limits and data usage policies, reducing the risk of service interruptions.
3. Core Architecture of a Multi‑Agent Scraping → Enrichment → Outreach System
A robust ai outreach agent is not a single script; it is a system of interacting agents, each with a specific domain of responsibility. This multi-agent ai workflow mimics a human operations team: one agent finds the leads, another checks their quality, a third researches them, and a fourth drafts the message.
Unlike linear automation (Step A → Step B → Step C), a multi-agent architecture is event-driven and stateful. It uses message queues (like RabbitMQ or Kafka) to handle asynchronous tasks, allowing the system to scale horizontally.
The Unified Pipeline Blueprint
The architecture generally flows as follows:
1. Scraper Agent: Identifies targets and extracts raw data.
2. Validation Agent: Checks data integrity and NAP (Name, Address, Phone) consistency.
3. Enrichment Agent: Augments raw data with external attributes (social profiles, tech stack).
4. Categorization Agent: Uses LLMs to segment businesses into precise personas.
5. Outreach Generator: Drafts personalized copy based on enriched attributes.
6. Sender Agent: Routes the message to the optimal channel (Email, LinkedIn).
For a deeper dive into how engineering-grade orchestration works, you can explore the technical breakdowns on the NotiQ Blog.
Scraper Agent (Google Maps → Structured Data)
The Scraper Agent is responsible for the initial ingestion of data. To handle google maps lead generation automation effectively, this agent must employ sophisticated navigation logic.
• Geographic Bounding: Instead of searching "restaurants in New York," the agent divides the map into small grid coordinates (bounding boxes) to ensure comprehensive coverage without hitting result limits per search.
• Scroll & Pagination: The agent simulates human scrolling to trigger lazy-loading elements, ensuring all results in a list are captured.
• API Fallbacks: When frontend extraction becomes unstable or risky, the agent should automatically switch to the official Google Places API to fetch the required data, ensuring continuity.
Enrichment Agent (Validation → NAP Consistency → Attribute Expansion)
Raw map data is rarely enough for high-conversion outreach. The Enrichment Agent takes the raw business name and website and performs a "deep dive."
• Source Switching: If the primary data source lacks a CEO's name, the agent queries secondary databases or performs a targeted site scrape.
• Mismatch Resolution: If the website domain listed on Maps redirects to a different URL, the agent updates the record.
• Confidence Scoring: The agent assigns a score to the data (e.g., "Email Validity: 95%"). If the score is below a threshold, the lead is flagged for manual review rather than being sent to outreach. This lead enrichment workflow prevents low-quality data from polluting your CRM.
Outreach Agent (Personalization → Sequencing → Channel Routing)
Once data is validated, the Outreach Agent takes over. This agent decideshowto contact the lead.
• Channel Routing: If the business is a digital agency, the agent might prioritize LinkedIn. If it's a local plumbing service, it might prioritize email or a contact form submission.
• Persona Matching: Using the enriched categories, the agent selects the correct "voice" for the message. An outreach agent doesn't just fill in blanks; it constructs a strategy.
4. How AI Handles Reliability: Rate Limits, Retries, and Data Validation
The difference between a hobbyist script and an enterprise-grade multi-agent ai workflow is reliability engineering. When you are processing thousands of records, failures are statistical certainties. Your system must be designed to handle them gracefully.
Rate Limits & Quota-Aware Scheduling
Google Maps and external enrichment APIs enforce strict rate limits to prevent abuse. A naive scraper hits these limits and crashes. A smart agent uses quota-aware scheduling.
• Dynamic Sleep Intervals: The system randomizes delays between requests to mimic human behavior and avoid triggering anti-bot protections.
• Request Normalization: If the system detects it is approaching a limit, it queues tasks for later execution rather than forcing them through.
• Compliance: Always refer to the Places API rate limits FAQ to understand the hard constraints of the official API, which serves as the baseline for safe automation pacing.
Retry Logic, Fallback Agents & Redundant Paths
In a google maps automation workflow, resilience is achieved through redundancy.
• Circuit Breaking: If an agent encounters repeated errors (e.g., 5 consecutive timeouts), the "circuit breaker" trips, pausing that specific module to prevent cascading failures while alerting the admin.
• Exponential Backoff: When a request fails, the agent retries after 2 seconds, then 4, then 8. This standard engineering practice prevents swamping a server that is struggling.
• Fallback Agents: If a specific scraping method is blocked, the system can automatically route the task to a pre-configured fallback method (e.g., switching from a headless browser to an API call) without stopping the entire pipeline.
Data Validation Layer (LLM-Based & Rule-Based)
Data quality is not just a preference; it is a compliance requirement. The Validation Agent ensures that your lead data validation meets strict standards.
• Schema Validation: Ensures that phone numbers follow the E.164 format and emails adhere to standard syntax.
• NAP Consistency: Checks if the Name, Address, and Phone number on the website match the Google Maps listing. A mismatch often indicates a business has moved or closed.
• Anomaly Detection: LLMs can review the data for logical inconsistencies (e.g., a "Bakery" category assigned to a business named "Smith Law Firm").
Adhering to high standards protects your business. For instance, the FTC data quality guidelines emphasize the importance of accuracy when using data for commercial decisions, reinforcing the need for robust validation layers.
5. AI‑Driven Personalization and Enrichment for Local Business Outreach
Generic outreach is dead. To convert local businesses, you must demonstrate that you understand their specific context.AI outreach personalization allows you to scale this relevance.
Attribute Extraction → Messaging Logic
The enrichment phase should extract specific attributes that fuel your messaging logic.
• Review Sentiment Analysis: The AI can analyze the business's Google Reviews. If they have a high rating, the outreach can congratulate them. If they have complaints about "slow service," a software solution pitch can pivot to "efficiency and speed."
• Service Menu Extraction: For a spa or clinic, the agent can identify high-value services (e.g., "CoolSculpting" vs. "Massage") and tailor the pitch accordingly.
• Conditional Logic: The system uses "If/Then" frameworks: If [Industry] = "Dentist" AND [Reviews] < 4.0, THEN use [Reputation Management Template].
Dynamic Email Drafting & Multi-Variant Testing
Modern ai outbound systems do not use static templates with simple variable insertion. They use LLMs to draft unique variants.
• Template Scaffolding: You provide the structure (Hook, Value Prop, CTA), and the LLM fills in the content based on the lead's enriched data.
• Creativity Controls: By adjusting the "temperature" of the model, you can control how creative the AI is. A lower temperature ensures professional consistency, while a higher temperature can be used for A/B testing different hooks.
• Evaluation Loops: A separate "Editor Agent" can review the drafted email against a set of best practices (e.g., "Is the CTA clear?", "Is the tone too aggressive?") before it is approved for sending.
Deliverability & Quality Safeguards
Even the best email is useless if it lands in spam. An automated outreach pipeline must include infrastructure for deliverability.
• Warming & Throttling: New domains must be warmed up gradually. The system should automatically throttle sending volume based on domain age and engagement rates.
• Domain Rotation: To protect your primary brand, the system should rotate between multiple sending domains.
• Inbox Placement: Monitoring where your emails land is crucial. For advanced insights into email infrastructure and deliverability optimization, platforms like Scaliq provide the necessary tooling to ensure your AI-generated emails actually reach the inbox.
6. Where Human Oversight Fits in an Autonomous Pipeline
While the goal is an autonomous ai outreach agent, human oversight remains critical for strategic direction and safety. "Human-in-the-loop" (HITL) design ensures that the AI amplifies human intent rather than replacing human judgment entirely.
Audit Logs & Observability
You cannot improve what you cannot measure. A production-grade pipeline requires deep ai observability.
• Enrichment Accuracy: Regularly sampling the data to verify that the Enrichment Agent is correctly identifying decision-makers.
• Scraper Uptime: Monitoring the success rate of the scraper agents. A drop in success rate usually indicates a change in the target site's structure.
• Reply Rates: If positive reply rates drop, it may indicate that the personalization logic needs tuning.
Fail‑Safes & Intervention Protocols
Reliability engineering requires fail-safe automation. The system should have defined thresholds that trigger an automatic pause.
• Error Spikes: If the error rate exceeds 5% in a 10-minute window, the pipeline pauses and alerts an engineer.
• Low Confidence Scores: If the Enrichment Agent reports low confidence for more than 20% of leads, the batch is held for human review.
• Content Safety: Filters should prevent the AI from generating or sending content that violates brand guidelines or safety policies. This is where NotiQ ’s logging and control layers provide peace of mind, ensuring that autonomy never becomes a liability.
7. Advanced Strategies, Toolkit, and Next Steps
Building this system requires a stack that balances flexibility with stability. Here is how advanced teams approach the engineering.
Tooling Stack & Recommended Modules
• Scraping Engines: Tools like Puppeteer or Playwright for browser automation, combined with residential proxy networks to handle IP rotation.
• Enrichment APIs: Services like Clearbit, People Data Labs, or specialized local data APIs serve as the raw data sources for the Enrichment Agent.
• LLM Models: GPT-4 or Claude 3.5 Sonnet are excellent for the reasoning tasks (categorization and drafting), while smaller, faster models can handle simple extraction tasks to save costs.
• Orchestration: This is the glue. While you can code this in Python using libraries like LangChain, platforms like NotiQ provide the managed infrastructure to host these agents without maintaining your own servers.
Competitor Gaps & Differentiation
Many tools in the market, such as generic scrapers or email senders, lack the unified context of a multi-agent system.
• No Unified Pipeline: Competitors often force you to export a CSV from one tool and import it into another. A multi-agent workflow handles this handoff in milliseconds.
• Weak Validation: Most tools assume the data they scrape is correct. An autonomous outreach agent assumes data is incorrect until validated.
• Lack of Retries: Single-function scripts rarely handle edge cases well. By building a system with workflow orchestration at its core, you create a competitive advantage: reliability.
8. Conclusion
The era of manual list building is ending. As Google Maps remains a high-value source for local business data, the complexity of extracting and utilizing that data has outpaced what manual workflows can handle. By adopting a multi-agent ai workflow, businesses can transform a fragile, labor-intensive process into a resilient, always-on revenue engine.
The key to success is not just scraping more data, but engineering a system that prioritizes reliability, validation, and context-aware personalization. Whether you are building this stack internally or leveraging an automation-first platform like NotiQ, the future of outreach belongs to those who can automate with precision.
Ready to deploy your own autonomous workforce? Explore how NotiQ can help you orchestrate reliable, high-performance google maps automation workflows today.
Frequently Asked Questions
- Q1: Is Google Maps scraping legal when automated with AI agents?
- Scraping publicly available data is generally permissible, provided it does not infringe on copyright, breach terms of service regarding authenticated access, or disrupt the service. However, you must strictly adhere to Google Places API policies regarding attribution, caching, and data usage. Always consult legal counsel regarding your specific use case and jurisdiction.
Continue Reading
More articles you might find useful

How to Use Google Maps to Find Businesses With Weak Review Response Rates
Learn how to use Google Maps to spot businesses with weak review response rates, score the opportunity, and turn public signals into qualified local leads.
Read the article →
Google Maps Outreach for Creatives: Web Designers, Video Editors, Brand Studios
A beginner-friendly system for creatives to find local businesses on Google Maps, spot visible gaps, and send outreach that feels relevant instead of spammy. Learn how to turn simple research into steady local client opportunities.
Read the article →
How to Identify “High-Churn” Industries Using Google Maps Data (Outreach Goldmine)
Learn how to use Google Maps data to identify high-churn industries and uncover better outreach opportunities. This guide shows which signals to track, how to score churn, and when to prioritize a niche.
Read the article →